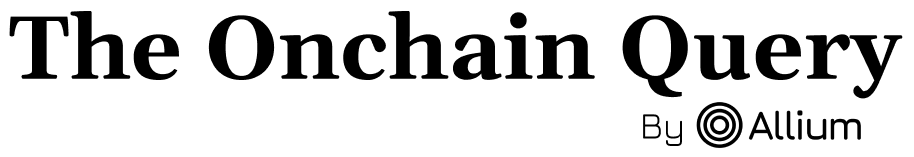
Building Real-Time Blockchain Data with APIs and Datastreams
Blockchain data pipelines often fail at scale. Learn how APIs, Datastreams, and continuous verification make real-time blockchain data reliable, fast, and scalable.

Every company building on blockchain faces the same challenge: users expect products that feel live.
Wallet balances should refresh instantly, dashboards should reflect the latest trades, and transactions should confirm in seconds.
Behind the scenes, though, the real-time onchain data that powers those experiences is anything but simple—fragmented across chains, prone to reorgs, and difficult to deliver in real time without breaking or lagging under scale.
Most teams start with APIs, webhooks, or polling. They work well for prototypes but collapse once scale and user expectations grow. APIs throttle, webhooks drop events, and reorganizations undo “confirmed” data. The result: stale balances, inconsistent dashboards, and missed transactions.
At Allium, we learned early that real-time blockchain data isn’t one system. It’s a set of complementary layers: APIs for on-demand lookups, Datastreams for continuous event delivery, and Datashares for verified historical context. Each handles a different part of the real-time problem.
1. Why Real-Time Blockchain Data Breaks at Scale
APIs and polling are simple to start with: call an endpoint, get the latest data. But when your product depends on continuous updates—like tracking thousands of addresses or millions of transactions—those requests multiply quickly.
Webhooks miss events when a connection fails or retry logic breaks. There’s no built-in replay, so gaps appear in the data.
APIs hit rate limits or get expensive as usage scales. Each new user means more requests, and costs rise with volume.
Polling introduces lag. Even short intervals mean you’re a few seconds behind the chain, and making them shorter adds load and cost.
Chain reorganizations create further inconsistency. A “confirmed” block might vanish after a fork, leaving downstream data out of sync.
These problems affect what end users see. Wallet balances lag. Dashboards drift from reality. Trading systems react to outdated prices.
The underlying issue is that blockchains emit a continuous stream of events, not discrete snapshots. Handling them as streams is the only way to stay aligned with the chain in real time.
2. When APIs Make Sense
APIs are the backbone of most blockchain products because they make real-time data easy to integrate where users actually interact with it. They’re designed for precision and speed—returning exactly what an application needs, on demand.
Allium’s APIs expose normalized blockchain data across addresses, tokens, NFTs, and smart contracts. Developers use them to fetch wallet balances, transaction histories, and market activity in milliseconds, without needing to manage nodes or indexers. Each request hits a unified schema that abstracts away the quirks of different blockchains, so teams don’t have to maintain separate logic for Ethereum, Solana, or Polygon.
This model fits interactive workloads—wallets, dashboards, and analytics apps—where end users expect instant feedback. A wallet refreshes a user’s holdings the moment they open it. A DEX tracker pulls live swap data as trades settle. A dashboard queries the latest transactions for a specific address. These are short, high-precision requests that don’t need to stream continuously.
At scale, the API layer also handles rate control and query optimization. Caching keeps common lookups fast, while pagination and time-range filters let engineers balance latency and cost.
3. When Datastreams Make Sense
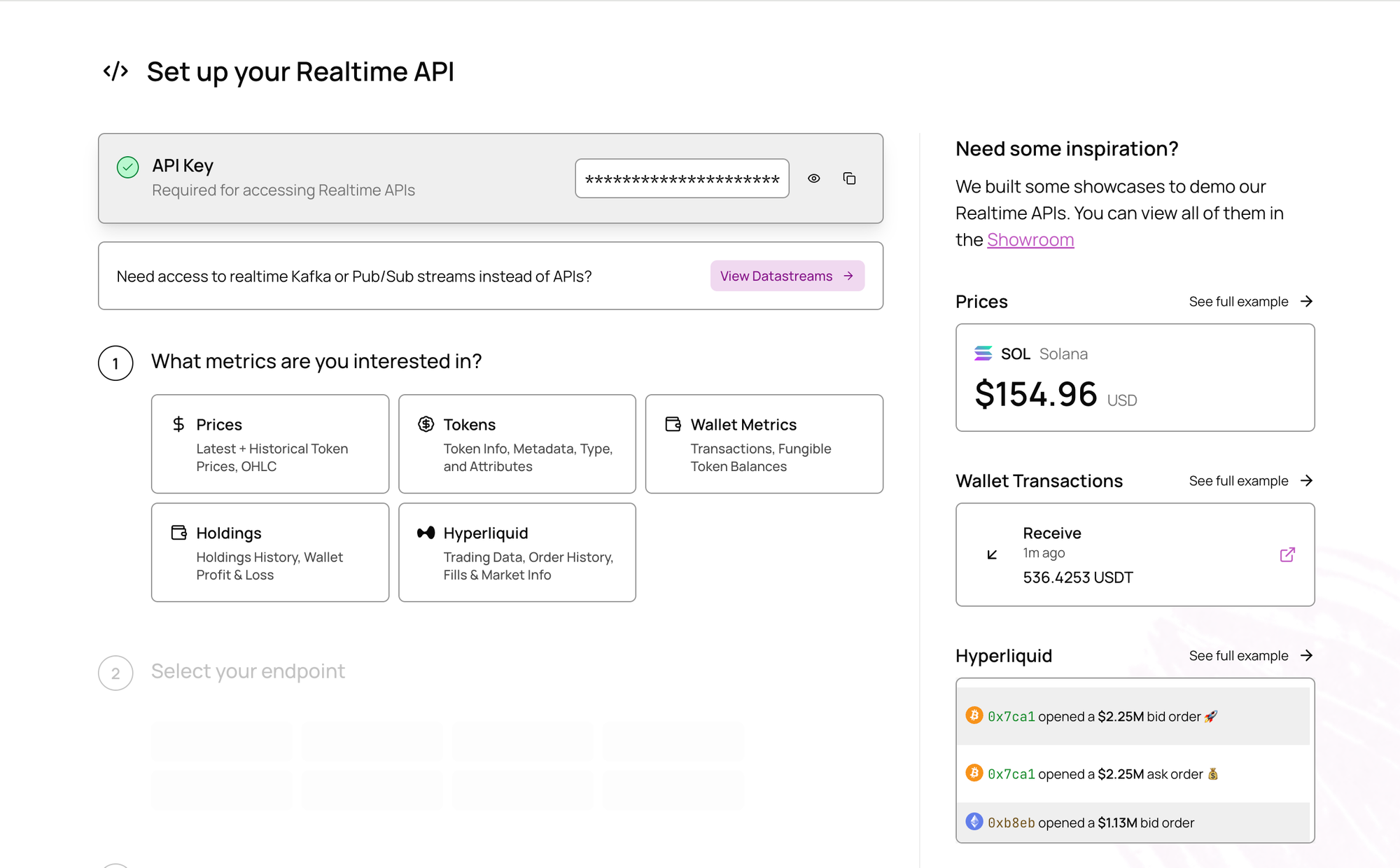
Datastreams power systems that need to react automatically to new blockchain events—analytics pipelines, monitoring, and internal ledgers that must stay continuously up to date.
Each stream represents a blockchain + entity pair such as ethereum.transactions or solana.balances. Events are delivered through standard interfaces like Kafka topics or Pub/Sub subscriptions, which means existing tooling can consume them directly.
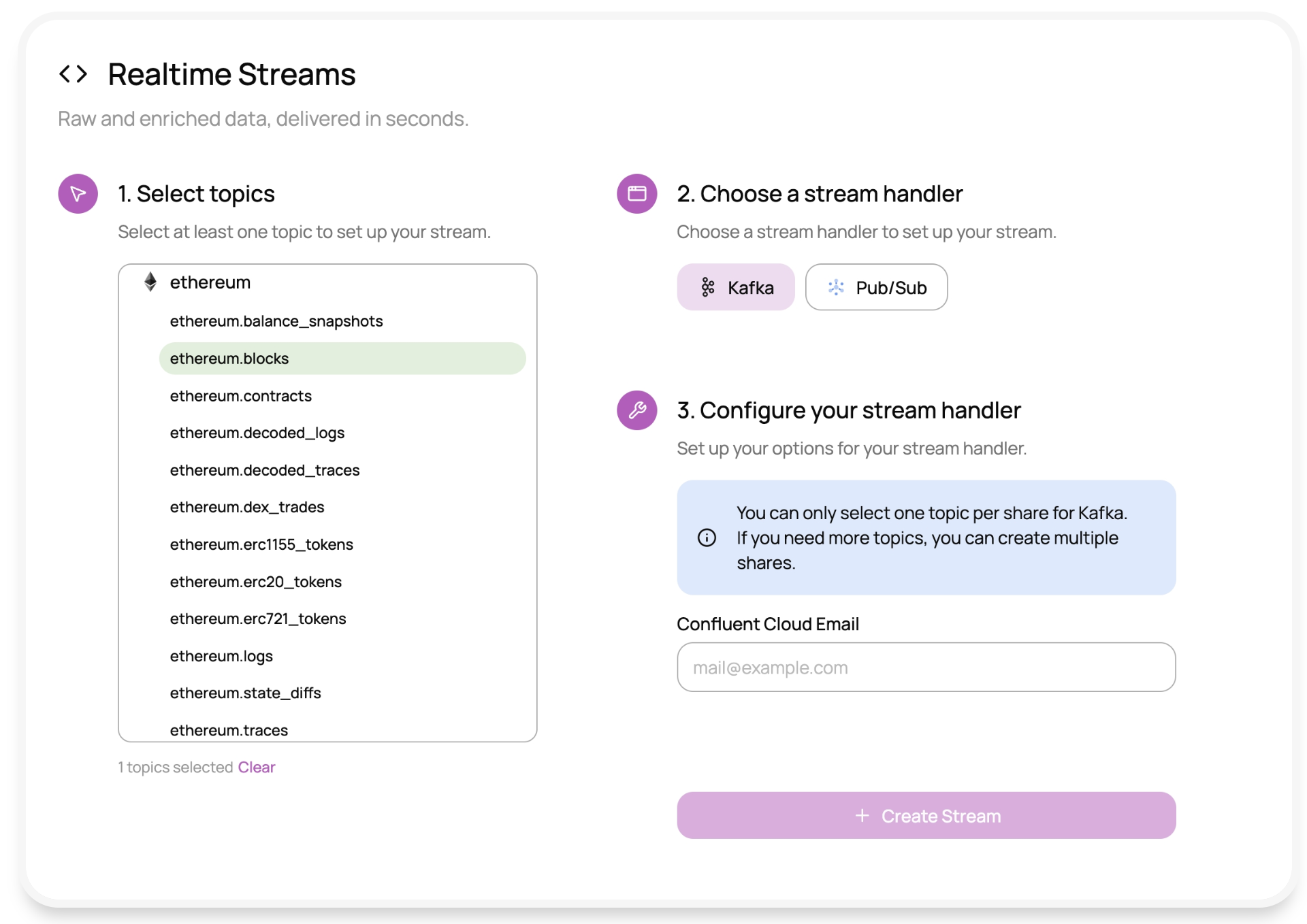
Under the hood, Datastreams keep state and replay history. If a consumer disconnects or a node lags, offset tracking allows the stream to pick up from the exact point it left off, guaranteeing that no data is lost. Data from multiple node providers is merged and validated before delivery, and background verification jobs continuously check that every block and transaction aligns with the chain’s canonical state.
Customers can choose between two delivery modes depending on the use case:
- Zero-lag streams publish events almost instantly from the latest block, ideal for dashboards or alerts.
- Lagged streams wait for block finality before emission, used in accounting, compliance, or risk systems.
Together these patterns make Datastreams reliable enough for production systems that depend on both speed and accuracy.
Many teams combine APIs with Datastreams: the API handles stateful lookups (“what’s the latest balance?”), and the stream captures the changes that update it (“a transfer just happened”).
Together they form the event-and-state loop most blockchain products rely on: APIs for what’s true right now, streams for what’s happening next.
4. Managing Filtering and Scale for Datastreams
At scale, data volume is the biggest challenge. A large wallet platform might watch millions of addresses but only care about a small subset. Without efficient filtering, those irrelevant events still move through the pipeline, driving up costs and latency.
Server-side filtering keeps systems efficient. Customers can define filters for specific wallets, contracts, or event types and update them dynamically. Only relevant data is streamed, which keeps throughput predictable as use cases grow.

5. How are Datashares different from Datastreams?
Data stream cover what’s happening now. Teams often also need the past—for reporting, auditing, or historical modeling.
Datashares fill that gap. They provide verified, queryable copies of blockchain data directly inside a customer’s data warehouse, using platforms like Snowflake, BigQuery, or Databricks.
Many Allium customers pair Datastreams and Datashares in a Lambda Architecture: streams capture live updates while shares handle historical backfill. Together they form a unified view of the chain, combining the speed of real-time data with the reliability of batch verification.
6. Data Verification in Real-Time Pipelines
Real-time systems rarely fail "out loud". Nodes lag, blocks arrive out of order, and reorganizations quietly rewrite history. If no one’s watching, small inconsistencies slip through and compound downstream.
Verification is the safeguard. Each step in a well-designed pipeline should check that every expected event arrived, that ordering makes sense, and that replicas match what was originally ingested. When discrepancies show up, the system needs a way to repair them automatically before bad data spreads.
At scale, this kind of verification becomes as important as the ingestion itself. It’s the difference between data that looks real-time and data that you can actually trust.
7.Real-Time Data is Expensive!
Blockchain data may be open, but turning it into something reliable at scale takes real effort. Each chain behaves differently, produces constant load, and needs its own monitoring, retry, and verification processes to stay consistent. Those jobs don’t disappear once the system is live—they grow with every new user and every added chain.
Teams that build their own ingestion pipelines usually discover that the hardest part isn’t standing them up; it’s keeping them running. Scaling brokers, repairing gaps, and managing failover quickly turn into ongoing operational work. The true cost of real-time isn’t in the servers—it’s in the people and time required to keep the data trustworthy.
8. Processing Close to the Source to Shorten Latency
Delivery is only part of the challenge. In data streaming, for example, once data is in, it still needs to be decoded, parsed, and transformed into useful formats.
We use tools like Apache Beam on Dataflow to process data in real time—extracting fields, decoding smart contracts, and shaping events into consistent schemas customers can query immediately.
Processing near the source shortens latency and avoids duplication across systems. It also lets teams run lightweight transformations or alerting logic directly on top of enriched streams. This approach gives customers both immediacy and control without requiring them to maintain their own complex processing layer.
9. Lessons for Teams Building Real-Time Systems
Years of operating large-scale blockchain data infrastructure have made a few principles clear:
- Use proven components for streaming and delivery. Reliability frees you to focus on data quality.
- Treat schema design as product design. Well-modeled data is easier to query and evolve.
- Build verification into the workflow from the start. Small inconsistencies multiply fast.
- Support multiple delivery options. Teams will have different stacks, and flexibility improves adoption.
Following these practices keeps systems stable and extendable as both data volume and use cases expand.
10. What’s Next: AI and Automation
As more data teams experiment with automation and AI, the biggest constraint isn’t the models—it’s the data feeding them. Even the most advanced systems depend on inputs that are complete, current, and consistently structured.
In practice, that means the work of building dependable data pipelines matters more than ever. Automated reconciliation, monitoring, and on-chain risk analysis all start with trustworthy event data that arrives on time and in order. Without that base, every downstream system becomes fragile.
AI will keep getting better, but the results will always mirror the quality of the data underneath. For anyone building in this space, the next breakthroughs will come from stronger foundations, not bigger models.
Making Real-Time Blockchain Data Work for Your Team
Delivering real-time blockchain data is difficult, but it doesn’t have to stay that way. With a thoughtful mix of APIs, Datastreams, and Datashares (for historical backfills), teams can meet users’ expectations for instant, reliable updates without losing control over cost or complexity.
That balance is what makes real-time systems sustainable. When data is verified, structured, and easy to access, engineers can focus on building products that respond to the chain as it happens—and users get the seamless experience they’ve come to expect.
If you’re exploring how to bring real-time data into your product or platform, we’d be happy to share what’s worked for other teams and help you find the best fit.
Get in touch or explore our docs.


