Blockchain’s Plumbing Problem: Why Enterprises Need a New Onchain Data Stack
Why blockchain data is so hard to use, and why enterprises now need an operating system for onchain data

Blockchains represent the world’s first open and publicly accessible dataset.
That’s revolutionary — in theory. Anyone, anywhere, can peek under the hood of a global financial system and inspect its raw state. Every block, every transaction, every contract call is right there onchain.
But in practice, that openness comes with a hidden cost. The data may be public, but it’s far from usable.
What looks like transparency is really a junkyard of raw materials: valuable, but unrefined. Yes, you can pull up Etherscan and see every transfer in every block. But try to build a reliable accounting system, trading strategy, or cross-chain dashboard, and you’ll quickly discover the what we call the data plumbing problem.
Before you can run a single analysis or write one line of code, you have to:
- Spin up and maintain your own RPC node (or pay someone who has)
- Extract and ingest terabytes of raw logs
- Normalize schemas
- Reconstruct blockchain state
- Continuously verify your data for reorgs and missing blocks
And if you’re working cross-chain? Repeat everything from scratch — each network has its own quirks, data formats, and failure modes (EVMs vs. non-EVMs, keeping up with new chains like Hyperliquid, etc.)

This article breaks down why blockchain data is so hard to use, and why enterprises now need an operating system for onchain data.
It’s the first in Allium’s new content hub — a space for insights, real-world questions, and data-driven research for teams building, analyzing, and operating with onchain data.
Subscribe so you don’t miss the next update.
The Myth of Free Blockchain Data
“Blockchain data is free.”
We hear that a lot — from institutions exploring crypto, from web2 engineers crossing over, and even crypto-native analysts who are used to getting most of the numbers they need from public dashboards.
It’s true: blockchain data is technically free and open to all. But “open” is not the same as “ready to use.”
People have grown accustomed to slick public dashboards and charts — the illusion that blockchain data simply appears in clean tables and tidy visualizations. What those views don’t show is how much heavy lifting happens behind the scenes: the parsing, backfilling, enrichment, and error correction that make the numbers trustworthy.
Every polished chart hides layers of data plumbing — hundreds of transformations, schema mappings, and verifications that most teams never see. Building those systems yourself means handling the same edge cases, outages, and reorgs that infrastructure providers quietly fight every day.
Free data got crypto through its hobbyist years. But as institutional finance, accounting, and risk systems move onchain, free doesn’t cut it anymore.
Every company operating, investing, and analyzing onchain needs:
- Accuracy — a one basis point error in a chart is fine; in an audit, it’s catastrophic.
- Depth — not just daily aggregates, but block-by-block granularity.
- Breadth — consistent coverage across every new chain, protocol, and standard.
The Data Plumbing Problem
Think of blockchain data like water: the source is open, but the pipes are leaky, inconsistent, and unfiltered.
Before you can drink from it — or build anything on it — you need filtration, pressure control, routing, and monitoring.
In blockchain terms, that means:
- Handling network outages and reorgs.
- Dealing with fragile RPCs that fail under load or change formats without warning.
- Running massive backfills to reconstruct historical data.
- Managing chain-specific architectures that break naive assumptions.
This is the invisible layer most teams underestimate. Let’s unpack each part.
Blockchain Constraints
Network Outages
Blockchain networks occasionally go dark. Nodes fail to reach consensus, software bugs cause forks, or updates trigger temporary splits.
When that happens, the flow of data stops. Indexers miss blocks or transactions, and the continuity of historical data breaks. If you’re ingesting directly from RPCs, you’ll see holes, inconsistencies, or stale data — often without warning.
Blockchain Reorganizations (Reorgs)
Reorgs happen when a node discovers a longer chain segment and switches over to it. That “longer” version becomes the canonical chain, invalidating previously accepted blocks.
Transactions you thought were final may disappear or move. For analytics or accounting pipelines, this is a nightmare — balances, volumes, and holdings can silently change after the fact.
Any institutional-grade data system must be reorg-aware, capable of detecting and reconciling these shifts automatically.
RPC Constraints
Raw blockchain data isn’t delivered in a neat relational schema. It comes through RPC (Remote Procedure Call) interfaces that return opaque, protocol-specific JSON blobs.
Even beyond decoding and transformation, RPCs introduce deeper challenges:
Version Changes
RPC providers often upgrade versions or alter endpoints. These changes can silently break downstream systems relying on stable output formats. Without redundancy across multiple providers and continuous verification, your data ingest will degrade or stop entirely.
Scalability Limitations
During high-traffic events — major airdrops, NFT mints, or even a viral token — RPC endpoints can fail. When that happens, block or transaction data stops flowing. Scaling horizontally across providers and geographies is non-trivial and costly.
Imagine your infrastructure collapsing during a once-a-year liquidity event. That’s what institutional reliability has to prevent.
Backfill Challenges
Ingesting live blockchain data is already complex. Historical data adds another magnitude of difficulty.
Ethereum alone has over 18 million blocks as of the time this article was written. Arbitrum has more than 300 million. Reprocessing all of that history, decoding logs, reconstructing balances, and ensuring consistency across schema versions requires serious compute and meticulous validation.
Backfills must also reconcile time-variant metadata — tokens that change decimals, protocols that upgrade, and price feeds that drift.
Every chain’s history is a multi-terabyte dataset that never stops growing.
Chain-Specific Edge Cases
Each blockchain is its own world.
- EVM chains (like Ethereum or Polygon) use account-based models.
- Move-based chains (like Aptos or Sui) use object-centric architectures.
- Cosmos chains expose state through Tendermint RPCs and IBC messages.
Even basic questions — like “What’s this wallet’s balance?” — require custom logic per chain.
Every difference compounds when you go cross-chain: new schemas, new state machines, new token standards. That’s why any claim of “universal blockchain analytics” without deep reconstruction is an oversimplification.
Transformation: Turning Raw Data into Useful Information
Getting the data is just the beginning. Turning it into something your analytics, accounting, or product teams can actually use is another story.
Data ETL and Standardization
Raw blockchain events need decoding, enrichment, and normalization. You have to:
- Ingest data from blockchain nodes
- Decode contract ABIs and event signatures.
- Resolve token metadata and decimal precision.
- Map addresses to known entities.
- Align schemas so queries work across chains and timeframes.
Without a common standard, every team reinvents the same transformations, wasting time and risking inconsistencies.
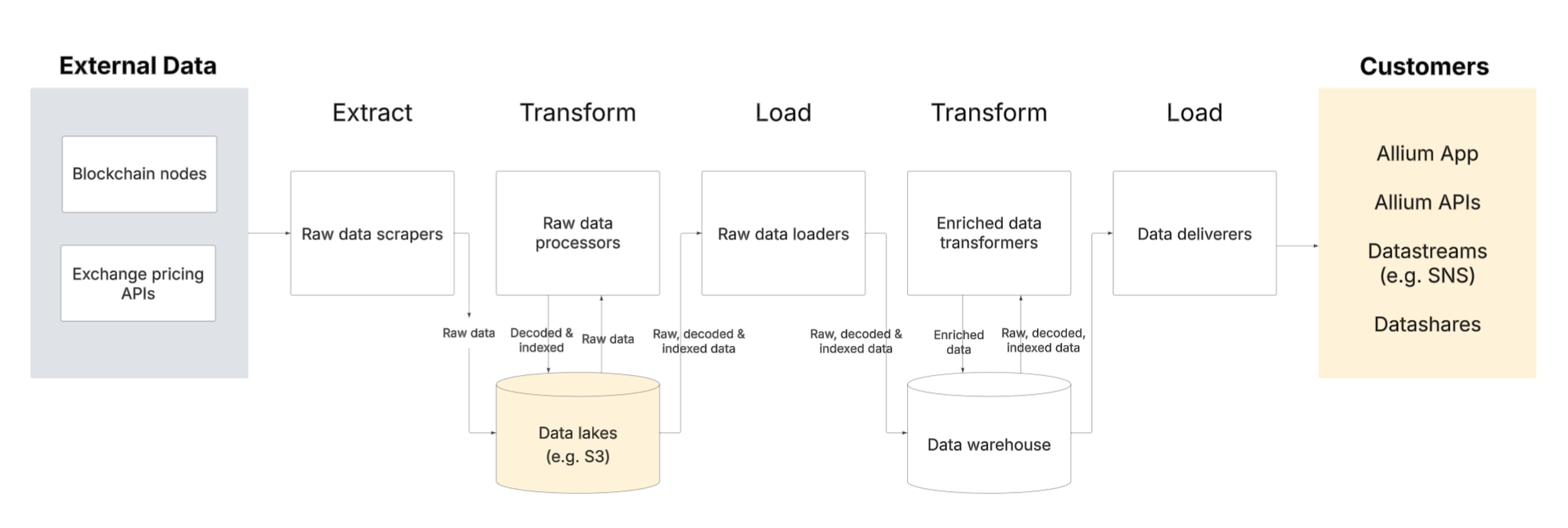
For example, this is a high level view of how Allium ingests, cleans, and serves data:
Pricing
Tokens need to be expressed in financial terms. That means integrating time-series price data from multiple venues, reconciling across liquidity profiles and methodologies. Each provider calculates differently, so reconciling token quantities to USD equivalents over time is a non-trivial join.
Scale
Now you have terabytes of enriched data — and users expecting sub-second queries. Optimizing for query speed, data freshness, and schema stability simultaneously requires sophisticated pipelines.
Why Typical Data Stacks Break
Most enterprise data teams eventually face the same question: Do we build our own onchain data infrastructure, or do we buy it?
At first glance, building seems logical. You already have engineers, cloud resources, and ETL tools. How hard can parsing a public dataset be?
In reality, typical Web2 data stacks weren’t built for the chaos of blockchains.
They assume:
- Stable schemas — tables don’t change shape every week.
- Consistent APIs — endpoints return predictable payloads.
- Finite datasets — history is bounded, and it doesn’t rewrite itself.
Blockchain data violates all three. It’s infinite, evolving, and self-referential — a living dataset where history can be rewritten by reorgs, smart contract upgrades, or even node version drift.
The “build” path quickly turns into an infrastructure treadmill:
- Weeks spent chasing reorg discrepancies.
- Constant schema migrations for new token standards.
- Compute bills ballooning from terabyte-scale backfills.
- Data pipelines pausing whenever a single RPC provider goes down.
Meanwhile, the real analytics, accounting, and product work stalls — not because your team lacks skill, but because the foundation underneath keeps shifting.
This is why even experienced engineering teams learn, often painfully, that the data plumbing layer determines whether your insights are correct or catastrophically wrong.
The New Standard: A Data Operating System for Crypto
Enterprises need a data stack built for how blockchains actually behave — not how Web2 systems pretend they do.
That means infrastructure that is:
- Accurate: verified, reorg-aware, and continuously validated against the canonical chain.
- Deep: block-level, call-level data parsed and enriched with full historical context.
- Broad: standardized across every major chain, protocol, and asset.
- Reliable: redundant ingestion and distribution to handle outages and spikes.
- Accessible: delivered where teams already operate — data warehouses, APIs, or event streams.
In short, a data operating system: A foundational layer that abstracts away blockchain complexity and delivers consistent, trustworthy data to every team — engineering, analytics, risk, accounting, and AI.
Think of it as the connective tissue between decentralized networks and institutional systems — translating raw blockchain noise into structured, verified truth.
That’s the layer our team has spent years refining: the operating system beneath the onchain data economy.
Quick Takeaways
- Blockchain data is public, but not production-ready.
- Outages, reorgs, and RPC drift make naïve ingestion unreliable.
- Every chain’s architecture introduces new reconciliation challenges.
- “Free” data becomes expensive once you need accuracy and scale.
- Enterprises need a data operating system — not just tools — to make onchain data usable.
This post is the first in The Onchain Query — Allium’s content hub for every team that analyzes, operates, and builds onchain, from ecosystem growth to AI analytics, investment research, and real-time apps. Here, we’ll answer the questions we hear most, share insights from the team behind the plumbing, and publish data-driven research.
📬 Subscribe to follow the series and get notified when new posts drop.


